
카프카 멀티 클러스터 환경에서 성능을 더 높일 수 있는 구조를 고민하다가 네이버 D2에서 Parallel Consumer를 설명한 글을 읽었다. 내용 설명이 너무 잘 되어 있어서 퍼오게 되었다.
Kafka를 사용하면서 메시지 동시 처리량을 늘릴 수 있는 가장 쉬운 방법 중 하나는 파티션을 증가시키는 것입니다. 다만 파티션 수는 한번 늘어나면 줄일 수 없기에 신중해야 합니다.
Log&Metric 조직에서는 Kafka를 활용하여 사내 로그 관리 시스템을 운영하고 있습니다. 방대한 양의 로그를 빠르게 처리하려다 보니 파티션 수가 굉장히 늘어나 있었으며 많은 파티션 수로 인한 사이드 이펙트도 존재했습니다. 파티션을 늘리지 않고도 동시 처리량을 늘리기 위해 고민하던 중 Parallel Consumer라는 라이브러리를 알게 되었으며 이후에 Parallel Consumer를 사용하여 적은 파티션으로 높은 동시 처리량 수준을 만족시킬 수 있었습니다.
이 글에서는 Parallel Consumer가 무엇인지, 어떻게 동작하는지 그리고 내부 구조는 어떤지 간략하게 공유해 보겠습니다. Kafka Client나 Producer에 대한 자세한 설명은 KafkaProducer Client Internals, KafkaConsumer Client Internals 등을 참고 바랍니다.
- 그냥 파티션 늘리면 안 돼?
- Parallel Consumer란 무엇인가
- Parallel Consumer의 순서 보장 방식
- Parallel Consumer의 내부 구조
- 성능 비교
- 마치며
그냥 파티션 늘리면 안 돼?
기존 Kafka Consumer의 병렬 처리 단위는 파티션이다. 보통 파티션별 단일 컨슈머 스레드가 할당되는 구조이기 때문에 동시 처리량을 늘리기 위해서는 파티션 수 또한 늘려야 한다. 파티션을 늘리면 동시 처리량은 늘겠지만 다음과 같은 단점이 존재한다.
1. 브로커 파일 시스템 리소스 사용량 증가
Kafka 브로커는 파티션별로 데이터를 저장하는데 이때 단순 데이터 정보(.log 파일)뿐만 아니라 메타 정보(.index, .timeindex, .snapshot 파일)도 함께 저장한다. 따라서 파티션이 많아질수록 많아지는 파일에 대한 파일 오픈 비용, 디스크 사용량 비용 등이 추가로 필요해진다.
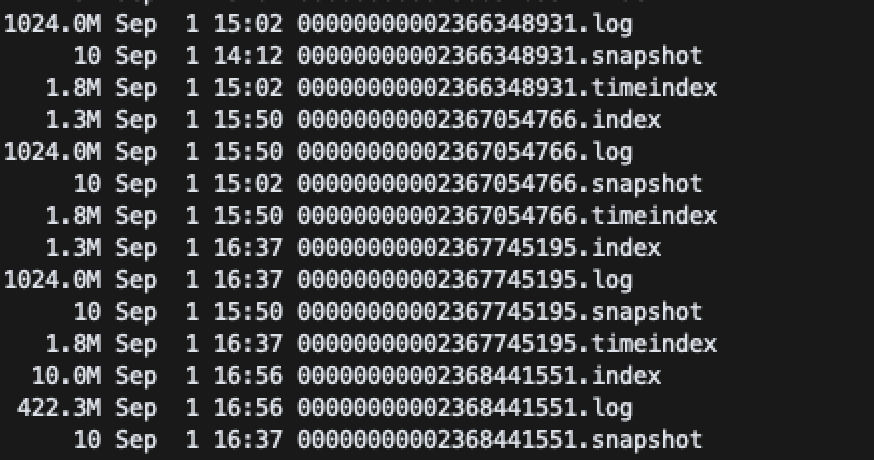
2. 장애에 더 취약한 구조
단일 브로커에 파티션 리더가 더 많이 배치되기 때문에 브로커 노드 장애 혹은 재시작으로 영향받는 범위가 더 넓다.
3. 복제 비용 증가
파티션 단위로 설정된 replicas 수만큼 복제가 이루어지기 때문에 복제로 인한 디스크 사용량, latency가 증가한다.
파티션 수가 적은 환경에서는 어쩌면 큰 문제가 아닐 수 있지만, 과도하게 늘어나 있는 환경에서는 문제가 될 수 있다.
Parallel Consumer란 무엇인가
Parallel Consumer는 Confluent Inc.에서 만든 오픈소스다(Apache 2.0 License). Parallel Consumer의 README를 살펴보면 이 라이브러리의 탄생 의도가 보인다.

간단히 말하자면 Parallel Consumer란 단일 파티션에 여러 컨슈머 스레드를 사용하여 파티션을 늘리지 않고 동시 처리량을 증가시키기 위해 만들어진 라이브러리이다.
파티션 단위 vs 메시지 단위
Parallel Consumer를 사용하면 병렬 처리 단위를 파티션이 아닌 개별 Kafka 메시지 또는 유사한 단위로 지정이 가능하다. 이해하기 쉽게 그림으로 비교해보면 다음과 같다. 첫 번째 그림은 일반 Kafka Consumer를 사용한 예시다. 파티션 단위로 병렬성을 달성해서 3개 메시지를 병렬로 처리하는 것을 볼 수 있다. 두 번째 그림은 Parallel Consumer를 사용한 예시다. 파티션이 한 개임에도 불구하고 복수의 스레드를 사용하여 첫 번째 그림과 동일하게 3개 메시지를 동시에 처리하는 것을 볼 수 있다.
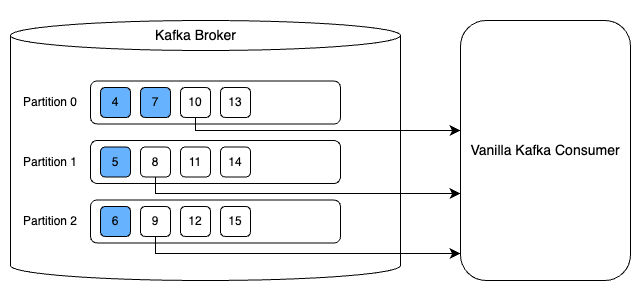
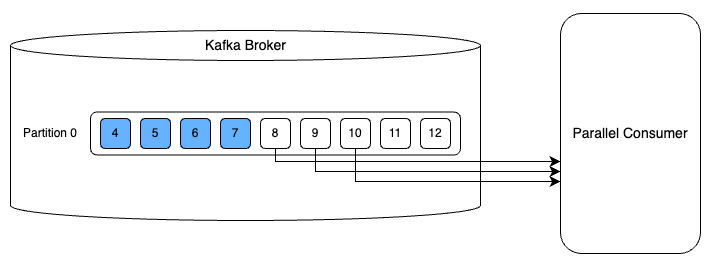
즉, 파티션 수를 늘리지 않고도 동시 처리량을 늘릴 수 있다는 이점이 Parallel Consumer와 일반 Kafka Consumer의 차이이다.
메시지 단위 병렬성이 어떻게 가능한가
기존 Kafka에서는 파티션별로 마지막으로 처리한 오프셋을 관리하고 있고 브로커의 오프셋 정보는 컨슈머가 메시지를 처리한 후 커밋을 하면서 갱신된다. 일반적으로는 한 번에 한 개의 메시지를 처리하며 auto 커밋 방식을 많이 사용한다.
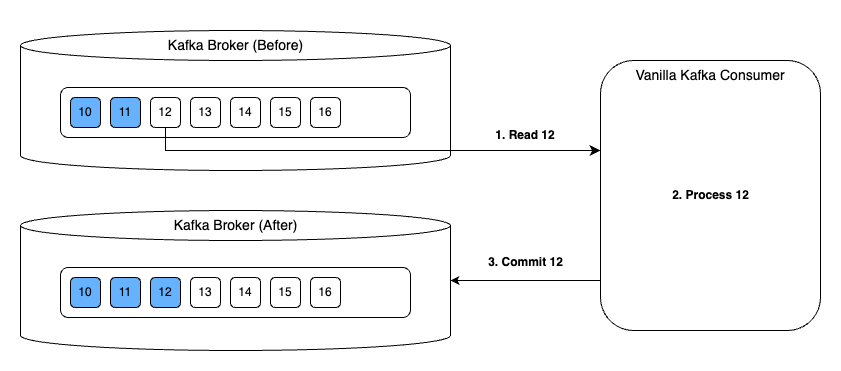
한 번에 한 개씩 처리하지 않고 여러 개의 메시지를 처리한 후 마지막 오프셋을 커밋할 수도 있다. 이때 커밋은 수동으로 직접 수행해야 한다.

여기서 메시지 처리는 실제 Kafka Consumer가 하는 것이 아니기 때문에 사용자가 이를 병렬로 수행하면 성능이 더 올라갈 수 있다. 이 경우도 마찬가지로 처리 후 마지막 오프셋을 커밋한다. 마찬가지로 커밋은 수동으로 수행해야 한다.

Parallel Consumer는 여기서 더 나아가서 오프셋 갱신을 비동기로 수행한다. 처리 결과를 임시로 저장해두고 주기적으로 오프셋을 커밋한다. 이렇게 하면 오프셋 커밋으로 인한 병목 없이 연이어서 처리할 수 있다. 아래의 그림은 11번 오프셋에 해당하는 메시지 처리 후 11번 오프셋을 저장하고 있다가 메시지 처리와 비동기로 커밋하는 과정을 보여준다. 커밋을 할 때 12, 13, 14번 오프셋에 해당하는 메시지를 동시에 처리하고 있는 것을 볼 수 있다.

메시지 처리를 병렬로 수행하면 어떤 오프셋을 처리해야 할지 모호할 수 있다. 예를 들어 한 파티션에서 12~14번 오프셋에 해당하는 3개의 메시지를 가져갔지만 병렬 처리로 인해 13번 오프셋을 처리하기 전에 14번 오프셋을 처리할 수 있다. Parallel Consumer는 누적하여 이전 오프셋들에 대한 처리를 완료한 가장 마지막 오프셋을 커밋한다. 다음 그림은 누적하여 12번 오프셋까지 처리를 완료한 상황을 보여준다. 14번 오프셋을 처리했지만 13번 오프셋을 아직 미처리 했기에 12번 오프셋을 커밋한다.
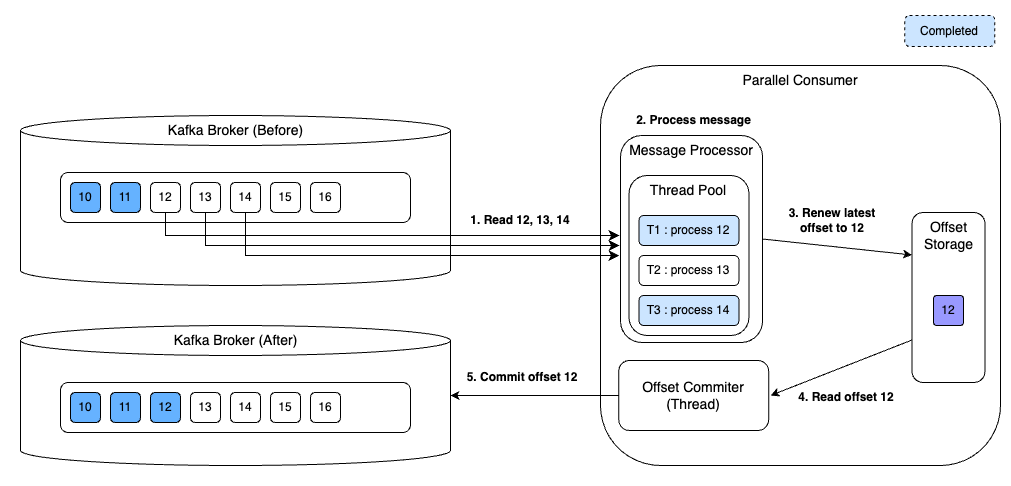
만약 13번 오프셋도 처리한 상황이라면 누적하여 14번 오프셋까지 처리 완료 했기에 14번 오프셋을 커밋할 것이다.

Parallel Consumer의 순서 보장 방식
지금까지 Parallel Consumer가 병렬성을 높이는 방법을 알아보았다. 메시지 병렬 처리 및 비동기 오프셋 관리를 통해 성능을 높일 수 있다. 하지만 메시지 간에 순서가 중요한 경우가 있다. 예를 들어 상품 주문에 대한 이벤트를 처리하는 경우 주문 요청 이벤트를 처리하기 전에 취소 요청 이벤트를 처리하면 문제가 될 수 있다. Parallel Consumer는 이를 위해 Partition, Key, Unordered 세 가지의 순서 보장 방식을 제공한다. Partition, Key, Unordered순으로 순서 보장 관련 제약이 느슨해지며 성능이 향상된다.
Partition

Partition 방식은 말 그대로 Kafka 파티션 단위로 순서 보장을 하는 것으로 원래 방식과 큰 차이는 없다. 이 방법은 서버 한 대로 여러 Kafka Consumer를 손쉽게 띄울 수 있어서 보다 적은 리소스로 처리할 수 있다는 점 외에는 큰 장점은 없다.
Key

Kafka 메시지에는 어떤 파티션으로 들어가야 한다는 힌트를 제공하는 Key가 있다. Parallel Consumer는 Key 단위의 순서 보장 방식이 있으며 이는 동일 Key 기준으로 메시지를 순차적으로 처리한다. 앞선 Partition 방식에서는 파티션 단위로만 병렬 처리가 가능한 반면에 Key 방식의 경우 동일 파티션 내에도 Key가 다르면 메시지가 병렬로 처리될 수 있다.
Unordered

마지막으로 Unordered 방식은 순서를 아예 보장하지 않는 방식이며 앞서 들어온 메시지의 완료 결과를 기다리지 않는다. 즉, 메시지 단위로 병렬 처리하는 방식이다. 특별한 제약이 없기 때문에 세 방식 중 성능이 가장 뛰어나다.
Parallel Consumer의 내부 구조
사용하는 라이브러리의 코드를 보며 내부 구현을 살펴보는 것은 해당 라이브러리를 목적에 맞게 더 잘 사용하고 추후 이슈 발생 시 원인 파악 및 대응에 큰 도움을 준다. Log&Metric 조직 내에서는 Parallel Consumer 코드를 면밀히 분석했으며 도중에 일부 버그를 찾아 기여하기도 했다. Parallel Consumer가 병렬성을 어떻게 달성하는지, 순서 보장은 어떻게 하는지 알아보았으니, 이제 내부 동작을 직접 확인해 보자. 관련 내용은 현재 이 글을 작성하는 시점에서 최신 버전인 0.5.2.7을 기반으로 작성했다.
아키텍처
Parallel Consumer에는 Broker Poller Thread와 Controller Thread라는 2개의 중요한 스레드와 실제 사용자 코드를 처리하는 Worker Thread Pool, 그리고 오프셋 저장소인 Work State Manager가 있다.
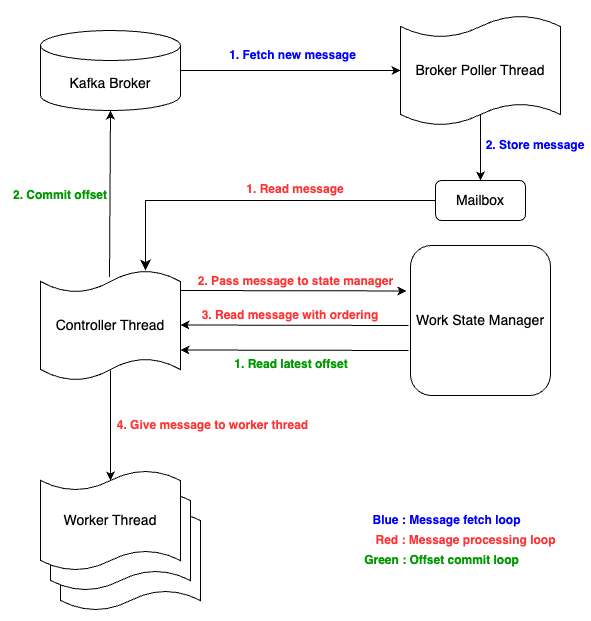
Broker Poller Thread는 실제 Kafka Broker와 통신하는 스레드로, 메시지를 가져와서 Mailbox에 저장한다. Controller Thread는 실제 메인 로직으로, Mailbox에서 메시지를 가져와서 Worker Thread에 전달하는 작업 및 메시지 커밋을 담당한다. Worker Thread Pool은 실제 사용자가 등록한 작업을 하는 스레드로, Controller Thread가 전달한 메시지를 처리한다. Work State Manager는 처리한 오프셋 및 순서 보장을 고려하여 다음에 처리될 메시지를 관리한다. 여기서 Mailbox는 Broker Poller Thread가 Controller Thread에게 polling한 Kafka 메시지를 전달하기 위한 매개체이다.
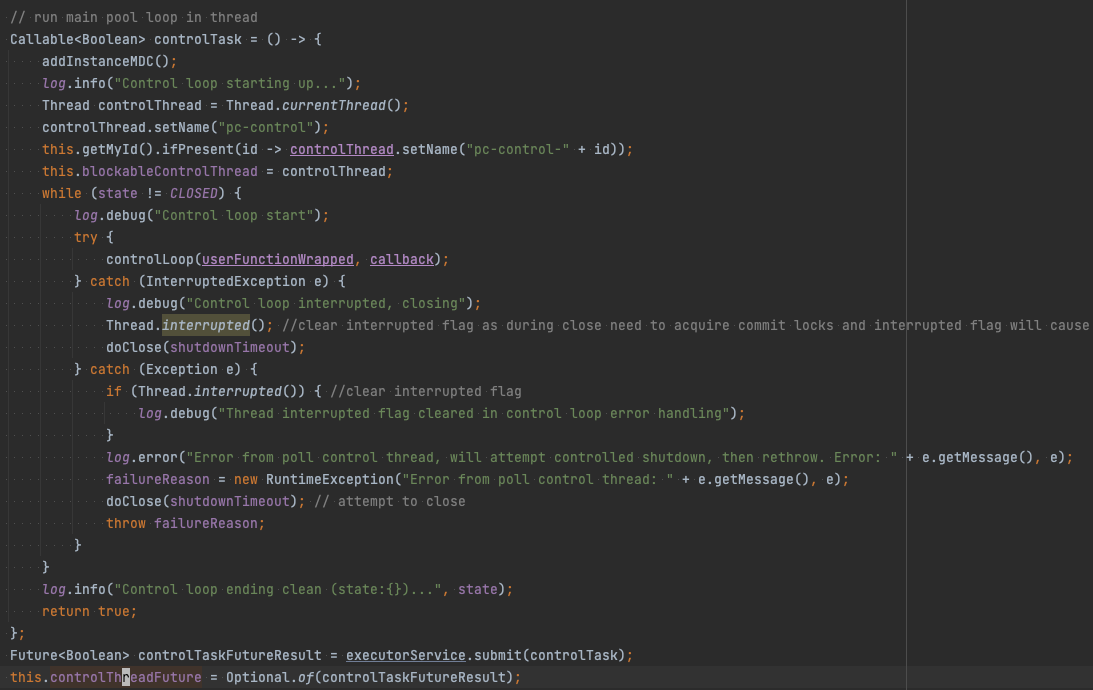
실제 코드를 간략히 살펴보자. 실제 코드를 살펴볼 때는 사용자가 직접 호출할 수 있는 메서드부터 보는 것이 좋다. 실제 사용자는 ParallelEoSStreamProcessor#poll을 주로 호출한다. 해당 메서드를 들어가 보면 wrappedUserFunc라는 것을 만들어서 AbstractParallelEoSStreamProcessor#supervisorLoop를 호출한다.

AbstractParallelEoSStreamProcessor#supervisorLoop는 Parallel Consumer 내부 구현의 핵심 메서드로, Broker, Control Loop 호출 등 거의 모든 작업을 트리거한다.

AbstractParallelEoSStreamProcessor#supervisorLoop 위쪽에서 BrokerPollSystem#start를 호출하는 것을 볼 수 있다. 이는 앞서 설명한 Broker Poller Thread에 해당하는 부분으로, 코드를 타고 들어가면 pc-broker-poll이라는 이름으로 스레드를 생성하는 것을 확인할 수 있다. handlePoll 메서드에서 Mailbox에 저장한다.

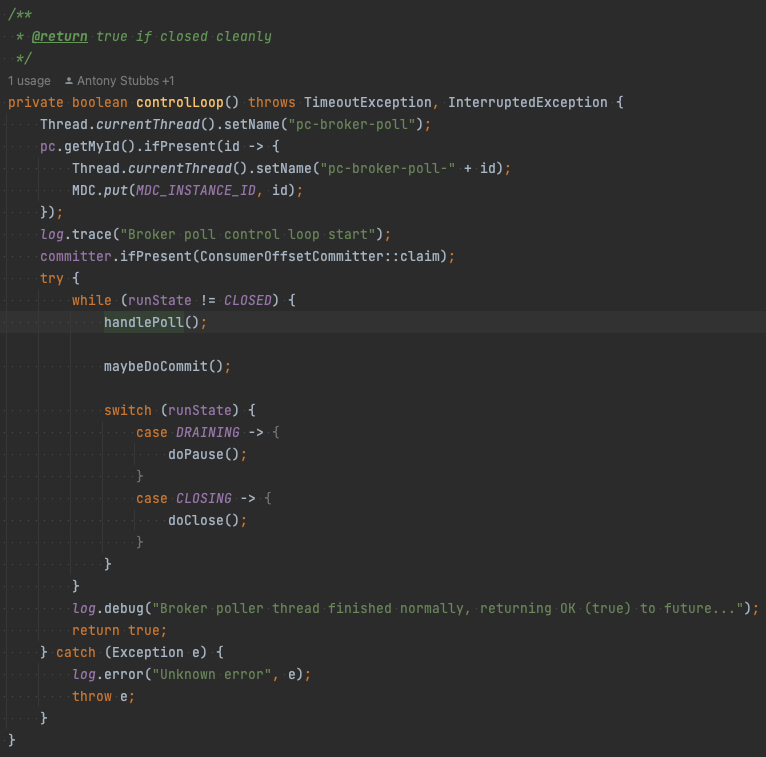
AbstractParallelEoSStreamProcessor#supervisorLoop 아래쪽에서는 controlTask라는 함수를 만든 후 ExecutorService에 넘기는 것을 볼 수 있다. 여기가 바로 Controller Thread를 생성하는 부분이다. 앞서 설명했듯이 Controller Thread는 Mailbox에서 메시지를 읽은 후 Worker Thread에 분배한다. 코드를 타고 들어가면 AbstractParallelEoSStreamProcessor#submitWorkToPoolInner 메서드를 호출하여 workerThreadPool에 submit한다.
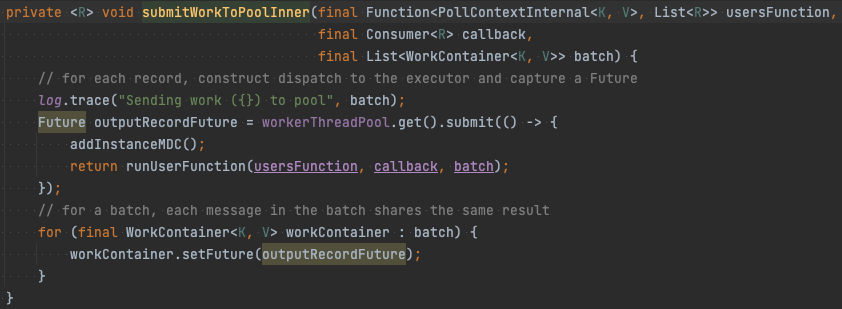
Worker Thread Pool은 AbstractParallelEoSStreamProcessor의 필드에 있는 것을 확인할 수 있다.
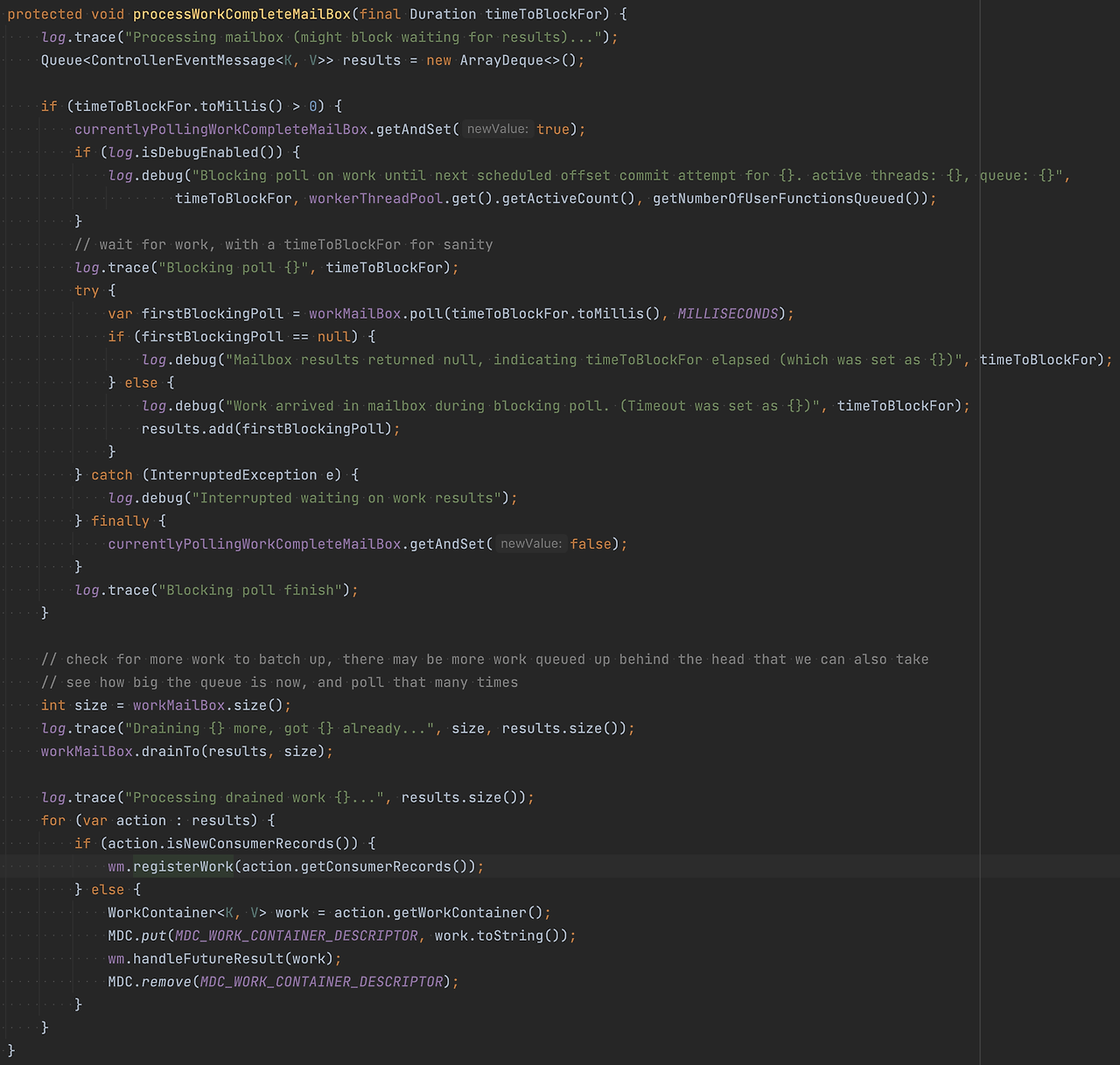
여기서 Control Thread가 Mailbox에서 가져오는 부분을 타고 들어가면 AbstractParallelEoSStreamProcessor#processWorkCompleteMailbox에 도달한다. 이 메서드에서 WorkManager#registerWork를 호출하여 Mailbox에서 메시지를 가져와서 WorkManager에 등록한다.
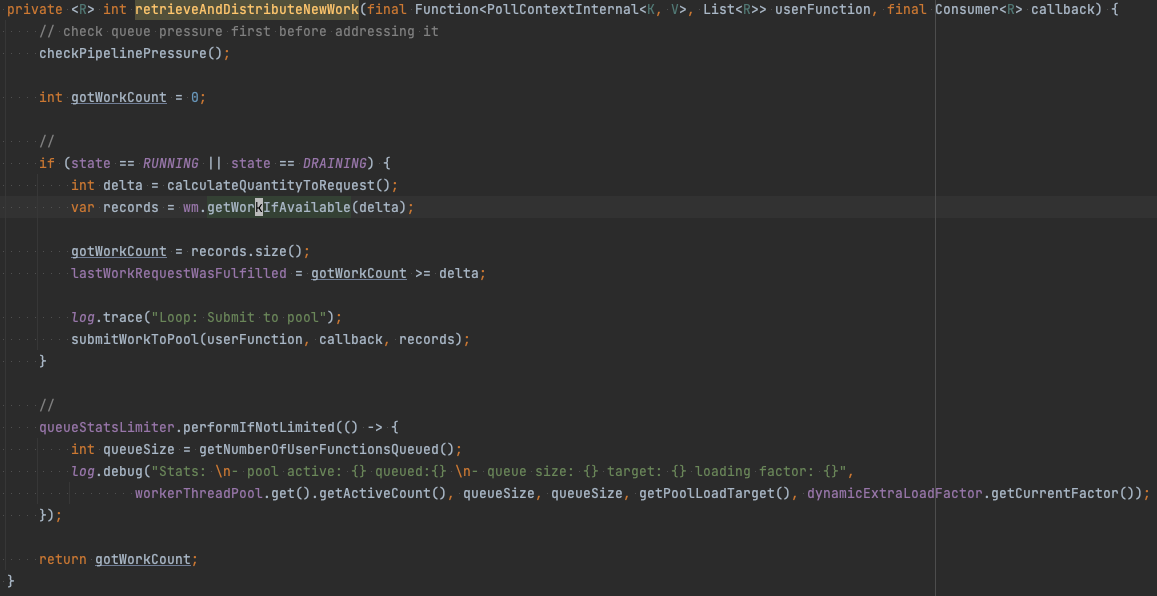
WorkManager에 등록한 메시지를 AbstractParallelEoSStreamProcessor#retrieveAndDistributeNewWork에서 WorkManager#getWorkIfAvailable를 호출하여 가져온다. WorkManager는 순서 보장을 고려하여 메시지를 반환한다.
순서 보장 방식 구현
위에서 언급한 순서 보장 방식을(Partition, Key, Unordered) Parallel Consumer는 어떤 식으로 구현하는지 살펴보겠다.

Parallel Consumer는 Kafka 메시지를 shard 단위로 분배하며, 각 shard별로 작업이 병렬 수행된다.
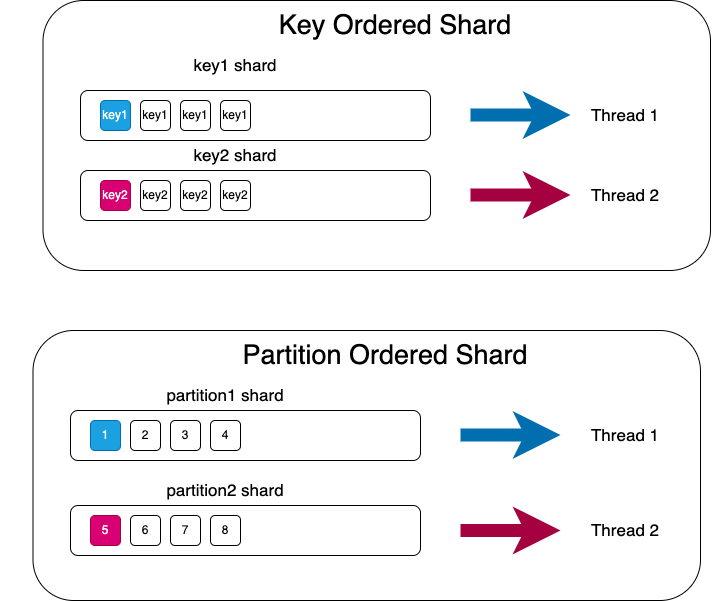
Key, Partition별로 shard가 생기고 shard 내에서 작업은 순서대로 처리되기 때문에, 단일 shard 내에서 메시지 처리 순서는 보장된다.

재밌는 것은 Unordered일 경우 Partition 개수만큼 shard가 생기지만 Partition shard 내의 메시지가 동시에 소비될 수 있다는 점이다.
즉, shard 내의 메시지를 1개씩 순서대로 처리하면 Key, Partition 방식의 순서가 보장되고, shard 내의 메시지를 동시에 여러 건을 처리하면 Unordered 방식이 구현된다.

ProcessingShard는 단일 shard를 지칭하는데 entries를 통해 작업 메시지를, key를 통해 shardkey를 관리한다.
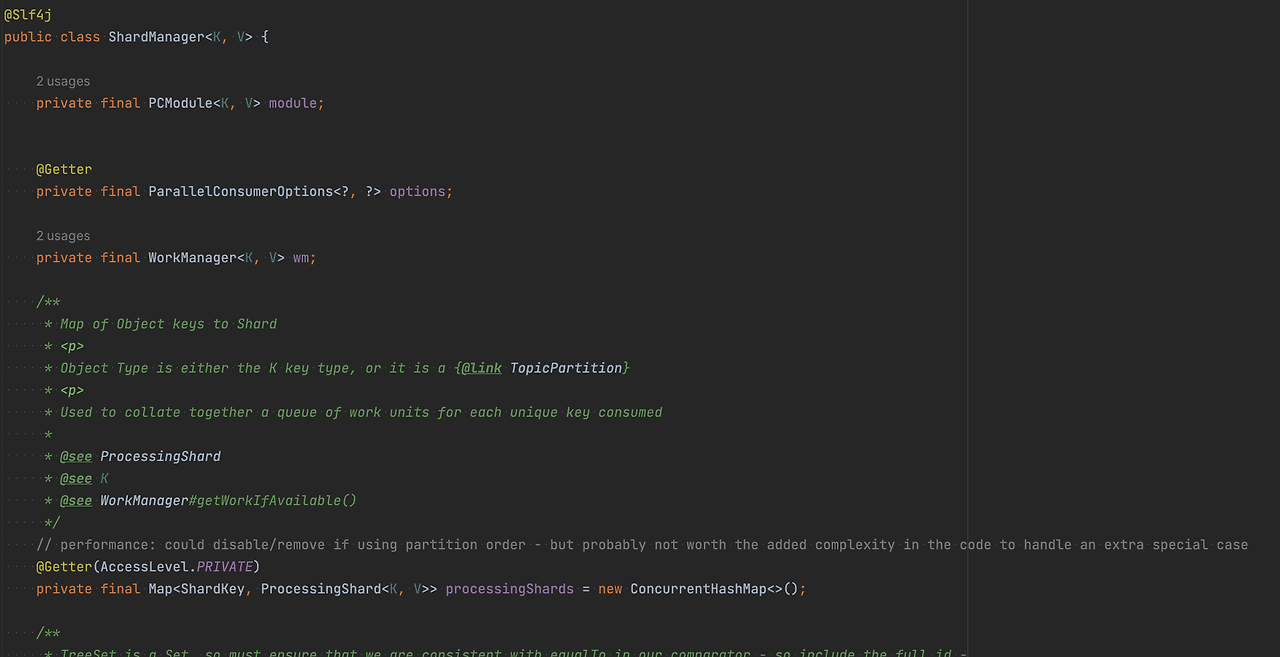
ShardManager는 모든 shard 정보를 관리하며, 각 shard별로 메시지를 가져와 WorkPool에 넘겨준다.

ProcessingShard#getWorkIfAvailable는 shard별로 처리할 task를 가져오는 메서드이다. 이때 ProcessingShard#getWorkIfAvailable를 보면 순서 보장이 필요한 경우(Key, Partition) shard별로 1건의 메시지만 가져오고, 순서 보장이 필요 없는 경우(Unordered) 병렬로 수행할 수 있는 최대의 메시지, 즉 batchSize만큼 가져온다.
batchSize, delta
batchSize는 단일 Worker Thread에서 한 번에 처리할 Kafka 메시지 개수, 즉 단일 스레드 chunk를 의미한다. delta는 전체 Worker Thread Pool에서 한 번에 처리할 Kafka 메시지 개수를 의미한다. 정리하면, 전체 shard로부터 delta만큼 task를 가져와서 각 Worker Thread에 batchSize만큼 task를 전달한다.
delta를 구하는 기본 공식은 workerThreadPoolSize * 2 * batchSize * batchSize이다. batchSize의 기본 값은 1이므로, 기본 값을 사용한다는 가정 하에 workerThreadPoolSize * 2라고 봐도 무방하다.
batchSize와 delta는 ParallelConsumerOptions으로 쉽게 수정 가능하다.

커밋
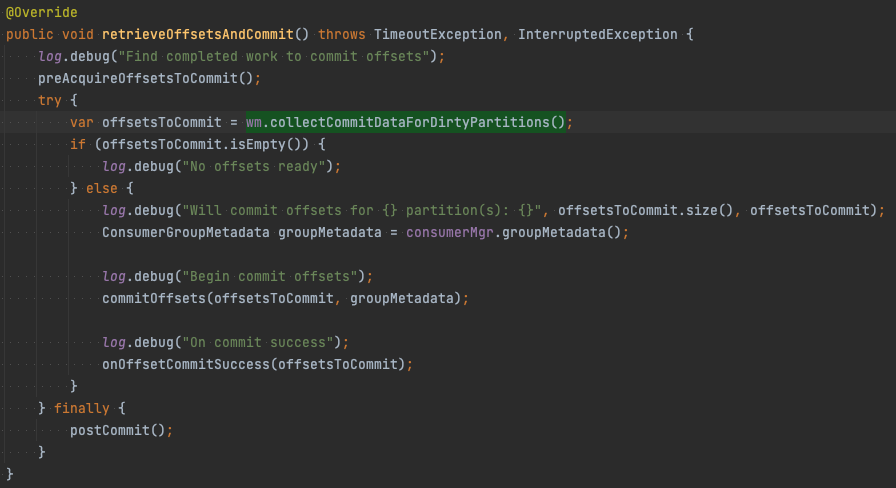
다음으로 먼저 커밋을 어디서 하는지 알아보자. 커밋은 Controller Thread에서 수행한다. AbstractParallelEoSStreamProcessor#controlLoop 위쪽을 보면 commitOffsetsThatAreReady라는 메서드를 호출한다.
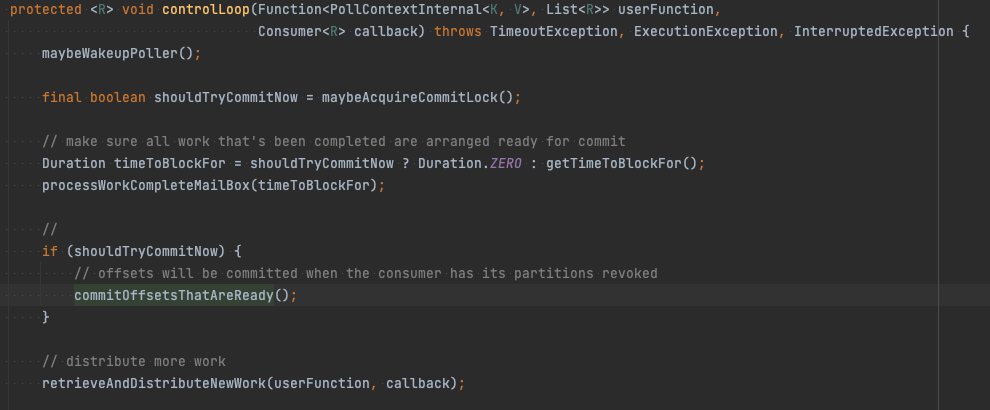
AbstractParallelEoSStreamProcessor#commitOffsetsThatAreReady 내부를 보면 commiter에게 OffsetCommitter#retrieveOffsetsAndCommit를 호출한다.
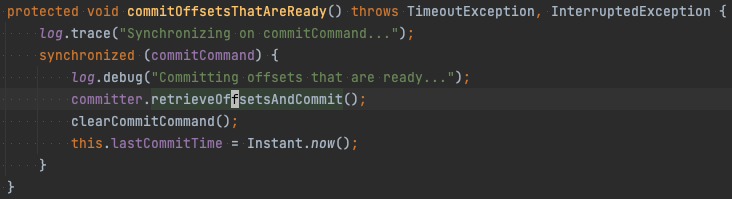
OffsetCommitter는 AbstractParallelEoSStreamProcessor의 필드에 있으며 생성자에서 옵션에 따라 어떤 OffsetCommitter를 쓸지 결정한다. OffsetCommitter 구현체는 앞서 설명한 Work State Manager에서 최신 오프셋을 가져와서 커밋한다.

오류로 인한 메시지 중복 처리 방지
예를 들어 한 파티션에서 4, 5, 6, 7번 오프셋을 처리 중 4, 6, 7번 오프셋은 성공했지만 5번 오프셋은 처리하지 못한 경우 4번 오프셋까지 완료했다고 커밋한다.

이때 장애로 서버가 재시작되면, 마지막으로 커밋한 오프셋을 4번으로 인식하고 5, 6, 7번 오프셋에 해당하는 메시지를 처리하려 할 것이다. 그런데 6, 7번 오프셋에 해당하는 메시지는 이미 처리했으므로 중복하여 재처리할 필요가 없다.
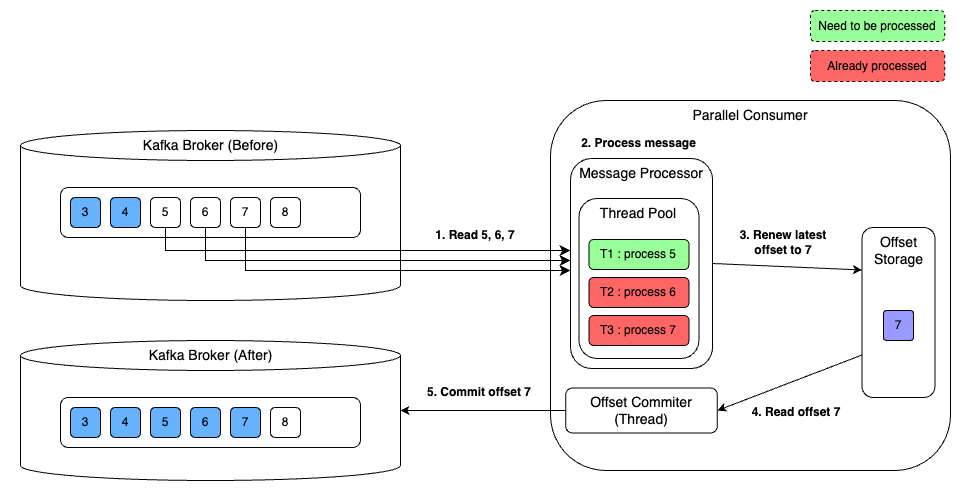
Parallel Consumer에서는 이런 상황을 방지하기 위해 완료되지 않은 오프셋들을 오프셋 메타데이터에 기록한다. 이를 incompleteOffsets이라고 부른다. 여기서는 5번 오프셋이 메타데이터에 기록될 것이다.

Parallel Consumer는 메시지를 처리하기 전에 오프셋 메타데이터에 있는 incompleteOffsets 정보를 확인하여 현재 메시지를 처리할지 여부를 판단한다. 여기서 incompleteOffsets에는 5번 오프셋만 있으니 6번, 7번은 건너뛰고 5번 오프셋에 대해서만 처리한다.

이제 구현을 살펴보자. 앞서 커밋을 할 때 AbstractOffsetCommitter#retrieveOffsetsAndCommit을 호출한다고 했다. 이 안에서는 WorkManager#collectCommitDataForDirtyPartitions를 호출한다.
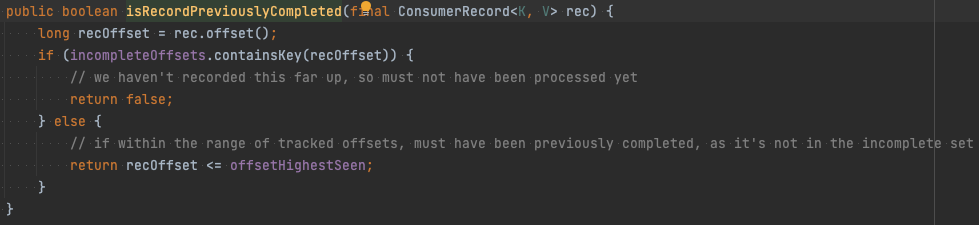
이를 따라가 보면 PartitionState#createOffsetAndMetadata에 도달한다. 여기서 커밋할 오프셋과 메타데이터를 만들어 주는 것을 확인할 수 있다. 여기서 PartitionState#tryToEncodeOffsets를 호출한다. PartitionState#tryToEncodeOffsets에서 성공한 것 중 가장 큰 오프셋과, 실패한 오프셋 리스트를 인코딩하여 반환한다.

앞서 저장한 메타데이터를 사용해서 PartitionState#isRecordPreviouslyCompleted에서 incompleteOffsets만 처리하게 필터링한다.
우아한 종료
마지막으로, 종료 시 어떤 일이 벌어지는지 알아보자. Parallel Consumer에는 DrainingMode라는 것이 있다.
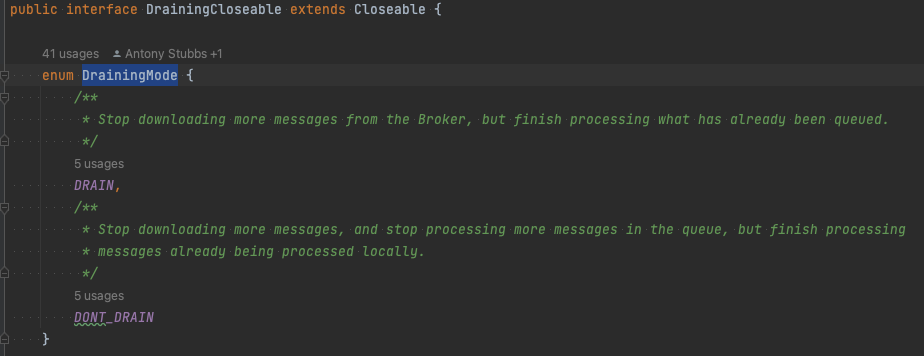
DrainingMode.DRAIN, DrainingMode.DONT_DRAIN 두 가지 방식이 있다. DrainingMode.DRAIN은 queue에 존재하는 메시지까지 다 처리 후 종료하고 DrainingMode.DONT_DRAIN은 queue에 들어간 메시지를 버린다. 두 방식 모두 종료 시 누적해서 마지막으로 처리한 오프셋에 대한 커밋은 한다.
실제 어떻게 사용되는지 코드를 살펴보자. AbstractParallelEoSStreamProcessor는 java.io.Closeable를 구현하여 close 메서드를 제공한다. close 메서드를 타고 들어가면 closeDontDrainFirst라는 메서드가 보인다. 이 메서드에서는 DrainingMode라는 것을 close 메서드에 넘긴다.
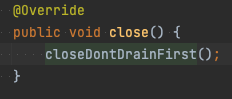
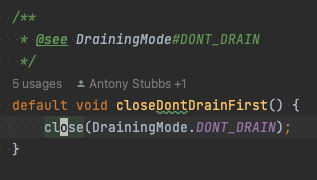
close 메서드를 타고 들어가면 DrainingMode에 따라 다르게 분기하는 것을 확인할 수 있다.

DrainingMode.DONT_DRAIN은 shutdownTimeout에 GRACE_PERIOD_FOR_OVERALL_SHUTDOWN만큼을 추가하여 기다린다. DrainingMode.DRAIN의 경우 drainTimeout만큼 추가로 기다린다. 각 분기에서 transitionToDraining, transitionToClosing를 호출하는데 이는 내부 state를 각각 DRAINING이나 CLOSING으로 바꾼다.
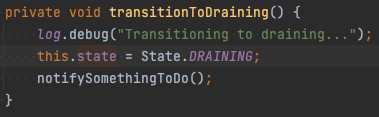
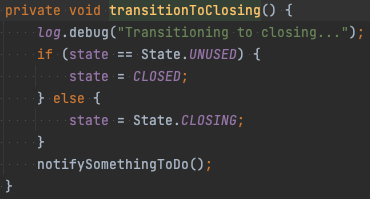
이렇게 상태를 바꾸고 AbstractParallelEoSStreamProcessor#waitForClose를 호출한다. AbstractParallelEoSStreamProcessor#waitForClose 내부를 보면 controlThreadFuture.get()을 호출하는 것을 볼 수 있다.
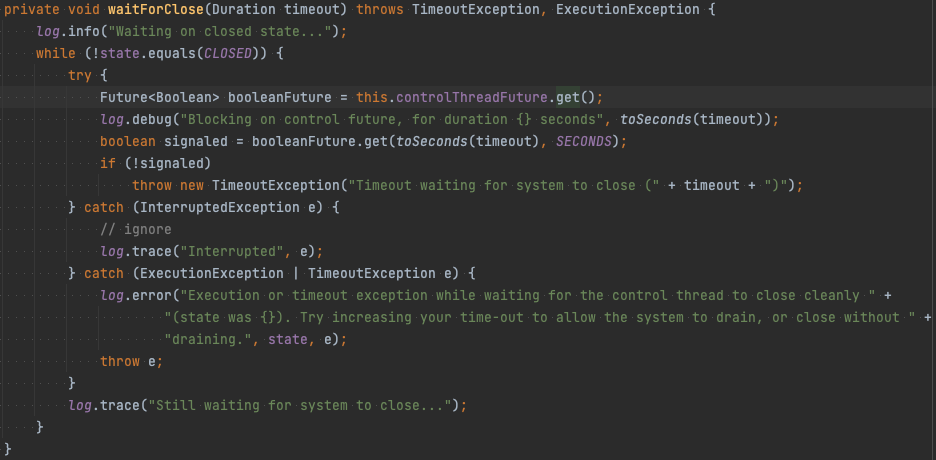
controlThreadFuture는 앞서 설명한 Controller Thread를 생성할 때 결과를 미리 Future로 바인딩해놓은 변수이다. Controller Thread는 state가 CLOSED가 아니면 계속 도는데 state를 바꿔서 이를 종료하고 결과를 controlThreadFuture에 받아서 종료를 확인한다.
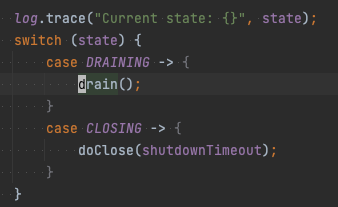
AbstractParallelEoSStreamProcessor#controlLoop 메서드 내부에서 앞서 설정한 state에 따라 AbstractParallelEoSStreamProcessor#drain 이나 AbstractParallelEoSStreamProcessor#doClose를 호출하는 것을 볼 수 있다. AbstractParallelEoSStreamProcessor#drain AbstractParallelEoSStreamProcessor#doClose 내부에서 오프셋 커밋, 잔여 queue 처리 등의 작업을 한다.
성능 비교
지금까지 Parallel Consumer가 어떻게 높은 병렬성을 달성하는지, 어떤 방식으로 순서를 보장하는지 알아보았다. 실제 성능이 어느 정도 차이날지 궁금하여 실제 동작하는 시스템을 일부 변경하여 성능 테스트를 진행해보았다.
테스트 Topic에 8개의 파티션을 생성 후 8개 Kafka Consumer를 띄운 것과 2개의 파티션을 생성하여 Parallel Consumer의 순서 보장 방식별로 각각 2개의 컨슈머를 띄운 것으로 테스트했다. 각 컨슈머는 4코어 16메모리로 수행했다. Key의 경우 0~99 사이의 임의의 값을 할당했다.

성능 테스트 결과 Parallel Consumer Unordered, Key 방식이 8개의 Kafka Consumer를 띄운 것보다 오히려 빠르게 처리하는 것을 확인할 수 있었다. Unordered 방식과 Key 방식이 거의 유사한 결과가 나온 이유는 Key를 0~99 사의의 다양한 값으로 균등하게 퍼트렸기 때문으로 보인다. Key 개수는 결국 shard 개수와 비례하기 때문에 많은 Key가 균등하게 분배만 된다면 Unordered와 유사한 수치의 성능을 낼 수 있다.
마치며
파티션을 늘리는 것이 항상 나쁜 것은 아니다. 트래픽도 적고 현재 파티션 수도 많지 않다는 가정 하에 단순히 파티션 1~2개 정도 더 늘리는 것으로 충분히 해결 가능한 상황도 있을 것이다. 단일 Kafka 메시지 처리 속도를 쉽게 향상시킬 수 있다면 먼저 그 부분을 개선하는 것이 좋다.
단일 Kafka 메시지 처리 속도를 단기간에 향상시키기 어려운 상황에서 이미 파티션이 과도하게 늘어나 있어 파티션을 더 늘리기 부담스럽다면 Parallel Consumer는 좋은 선택지가 될 수 있다.
다만 Partition 순서 보장 방식은 기존 방식과 큰 차이가 없어 메리트가 없기 때문에 *Key나 Unordered 순서 보장 방식을 사용할 수 있는 환경에서 사용하는 것을 권장한다. * 또한 Parallel Consumer가 트랜잭션 기능도 지원하지만 메시지가 정확히 1번만 전달되어야 하는 강한 제약 조건이 있는 환경에서는 권장하지 않는다. 오히려 디버깅에 어려움을 겪는 상황이 발생할 수 있다.
참고로 Log&Metric 조직 내에서는 평균 하루 5억 건 이상의 메시지를 처리하는 Kafka Consumer 컴포넌트에서 Unordered 방식으로 Parallel Consumer를 문제 없이 잘 활용하고 있다.
Parallel Consumer는 이 글 작성 시점 기준 0.5.2.7이 최신 버전이다. 아직 메이저 버전이 나오지 않았기 때문에 추후 버전에서 변경이 많아질 수 있다. 하지만 큰 구조나 개념은 달라지지 않을 것이다. 이 글이 Parallel Consumer가 무엇인지, 어떤 상황에서 사용해야 하는지 이해하는 데 도움이 되었으면 좋겠다.
출처: https://d2.naver.com/helloworld/7181840
'MessageQueue > Kafka' 카테고리의 다른 글
| kafka Spring Boot 연동하기, KafkaFactory로 컨슈머 팩토리 만들기 (0) | 2023.01.30 |
|---|---|
| kafka 왜 좋을까? (1) | 2023.01.30 |